Stable Diffusion极速上手及提示词使用教程
SD核心三要素:提示词(提示词分为:正向提示词、反向提示词)、模型、controlnet
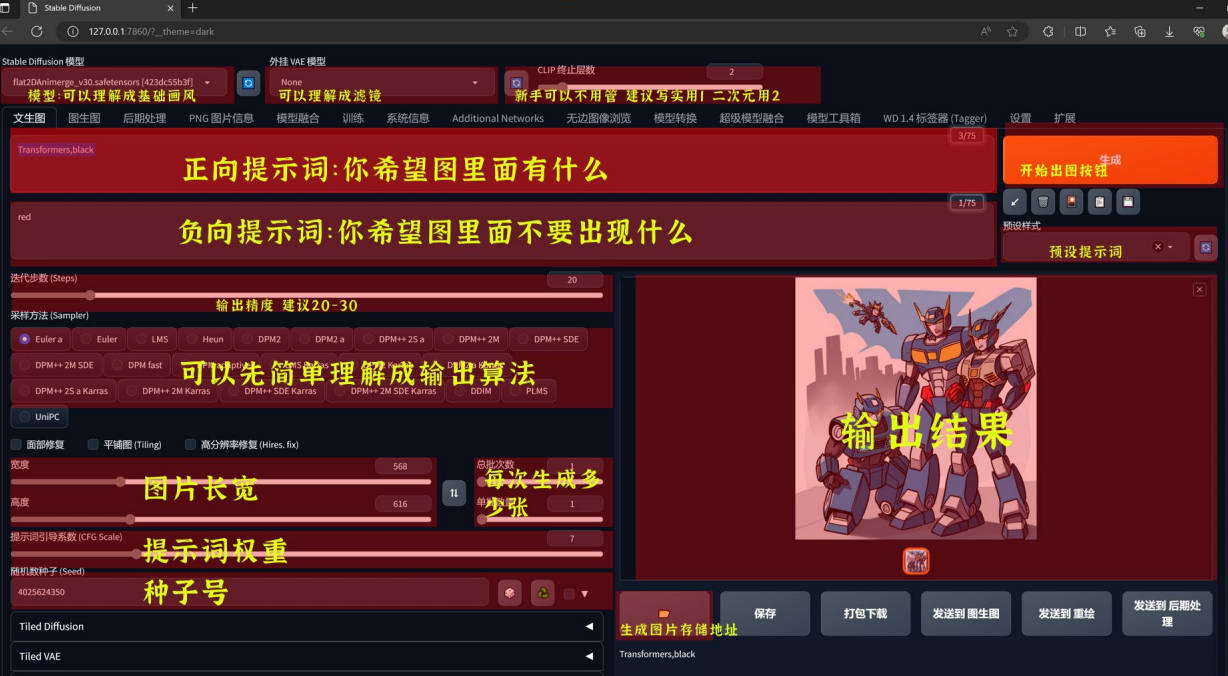
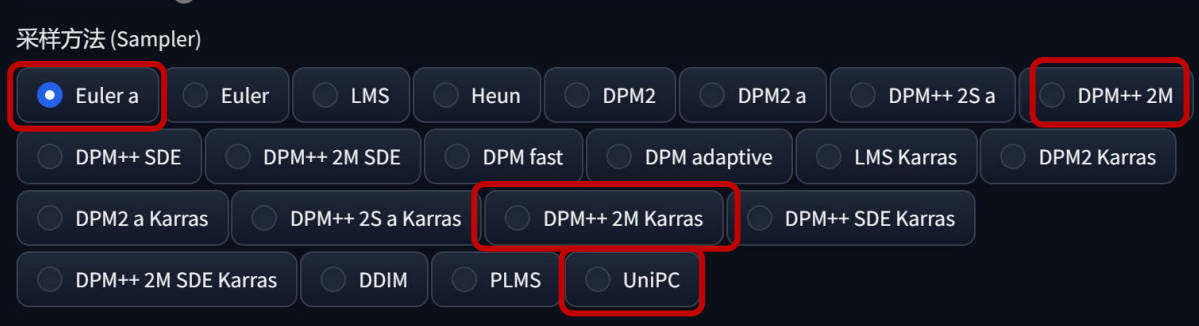
常用的采样方法
正向提示词(Prompt)
**人物【Who】😗*人物身份【man】 、发型发色【white long hair】 、五官特征【big beard】 、面部表情【smile】 、肢体动作【Raise one‘s arm】 、服装【dress】
**时间【When】😗*白天黑夜【day/night】 、特定时间【morning】 、环境与光【sunlight/bright/dark】
**地点【Where】😗*室内室外【indoor/outdoor】、场景【forest/street】 、道具【table/flower】
**事情【What】😗*生活日常【eat/sleep】 、娱乐活动【playing sth】
构图
视角:top view、front view、side view、rear view 景别:medium shot、 perspective、close-up
质量
画质:best quality、masterpiece、wallpaper

反向提示词(Prompt)
低质量:low quality / normal quality 畸形:extra limbs / too many fingers 不符合审美:age spot / skin blemishes
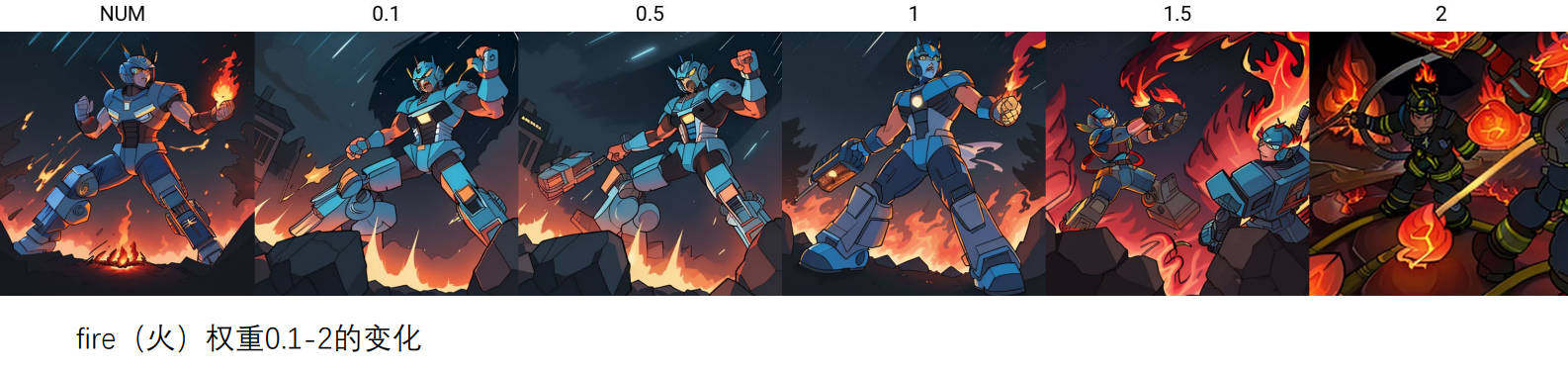
提示词权重格式
括号+数字: (Moon:1.5) Moon的权重变成1.5倍 (Moon:0.8) Moon的权重变成0.8倍
只加括号~~~
圆括号:(((Moon))) 每套一层权重增加1.1倍:1.1X1.1X1.1=1.33
中括号:{Moon} 每套一层权重增加1.05倍:1.05X1.05X1.05=1.16
方括号:[[[Moon]]] 每套一层权重增加0.9倍:0.9X0.9X0.9=0.73
提示词权重格式
通用提示词(Prompt)模版
以下的通用提示词模版中的提示词是SD文生图常用到的提示词,非常实用,有很多同学在刚开始用SD的时候,发现生成的图像各种问题各种出错,可能就是缺少以下通用提示词的原因,所以,现在我把这些提示词分享在这里让大家直接复制使用!
正向提示词(Prompt)后添加:
(masterpiece:1.2), best quality, masterpiece, highres, original, extremely detailed wallpaper, perfect lighting, (extremely detailed CG:1.2), drawing, paintbrush
负向提示词(Prompt)后添加:
NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots,acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated: 1.21), (tranny: 1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy: 1.21), (bad proportions:1.331), extra limbs, (disfigured: 1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
提示词案例解析1
提示词
(dramatic, gritty, intense:1.4),masterpiece, best quality, 8k, insane details, intricate details, earrings, hyperdetailed, hyper quality, high detail, ultra detailed, Masterpiece, 1girl,solo,underwater,bubble,air bubble,jewelry,bare shoulders,skirt hold,wet clothes, ress, white dress, super delicate face, face super, face as delicate as an angel,barefoot,puffy sleeves,float,(long hair, blue hair:1.4), blue theme,realistic, black background, white rose, many flowers, water as smooth as a mirror, beautiful detailed water, reflection pool, dynamic angle, floating, (real water,Realistic, 1.5, flowing)
提示词拆解
人物:1girl(一个女孩) - 发型发色:long hair, blue hair(长发,蓝色头发) - 五官特征:,face as delicate as an angel(与天使一样细腻的面孔) - 肢体动作:skirt hold(抓住裙子) -服装:wet clothes(湿身衣物),barefoot(赤脚) 地点:underwater(水下),reflection pool(反射池),real water(真实水体),flowing(流动),black background(黑色背景),white rose(白玫瑰),many flowers(很多花) 事情:无具体描述 构图:solo(单人),dynamic angle(动态角度),floating(漂浮) 质量:dramatic, gritty, intense:1.4(戏剧性、粗糙、激烈:1.4),masterpiece(杰作),best quality(最佳质量),8k(8K 分辨率),insane details(疯狂的细节),intricate details(复杂的细节),hyperdetailed(超级详细),hyper quality(超级质量),high detail(高细节),ultra detailed(超细致),realistic(逼真),super delicate face(非常细致的面部)
使用模型:墨幽人造人_v1040精简.safetensors

提示词案例解析2
提示词
solo, jewelry, earrings, pants, tattoo, gloves, fire, chibi, torn clothes, belt, black hair,brown gloves, black eyes, full body, torn pants, goggles, standing, fingerless gloves, hoop earrings, black background, denim, looking at viewer, v-shaped eyebrows,simple background, smoke, jeans, closed mouth, sleeveless, cowboy hat, Brown hat,Firefist Ace,
提示词拆解
人物:1girl(一个女孩) * 发型发色:black hair(黑色头发) * 五官特征:black eyes(黑色眼睛),v-shaped eyebrows(V字形眉毛) * 面部表情:looking at viewer(看向观众),closed mouth(闭嘴) * 肢体动作:standing(站立) * 服装:hat(帽子),pants(裤子),tattoo(纹身),gloves(手套),torn clothes(破烂服装),belt(腰带),denim(牛仔布料),sleeveless(无袖),cowboy hat(牛仔帽),Brown hat(棕色帽子),fingerless gloves(无指手套),hoop earrings(圈形耳环) 地点:black background(黑色背景),simple background(简约背景) 构图:solo(单人)
使用模型:墨幽人造人_v1040精简.safetensors

提示词案例解析3
提示词
1girl,in the sunlight, blue sky, reality, black hair, looking at viewer, depth of field,
提示词拆解
人物: 1girl (一个女孩) * 发型发色:black hair(黑色头发) * 面部表情:looking at viewer(看向观众) 地点: in the sunlight(在阳光下) , blue sky(蓝天) 构图: depth of field,(景深)
使用模型:墨幽人造人_v1040精简.safetensors

使用模型:majicMIX realistic 麦橘写实_v2威力加强典藏版

使用模型:大颗寿司Mix.safetensors

提示词案例解析4
提示词
(masterpiece),(best quality:1.2),official art,(extremely detailed CG unity 8k wallpaper),(photorealistic:1.4),1girl,future technology,science fiction,future mecha,white mecha,streamlined construction,internal integrated circuit,moisturizing texture,,upper body,driver's helmet,
提示词拆解
人物:1girl(一个女孩) * 服装:future technology(未来科技),science fiction(科幻),future mecha(未来机甲),white mecha(白色机甲),streamlined construction(流线型结构),internal integrated circuit(内部集成电 路),moisturizing texture(润泽的质感)driver's helmet(驾驶员头盔) 构图:upper body(上半身), 质量:masterpiece(杰作),best quality(最佳质量),official art(官方艺术),extremely detailed CG(极其精细的计算机图形),photorealistic(写实的),unity 8k wallpaper(Unity 8K壁纸)
使用模型:大颗寿司Mix.safetensors 
使用模型:XXMix_9realistic_v4.0.safetensors 
使用模型:majicMIX realistic 麦橘写实_v2威力加强典藏版 
使用模型:GhostMix_V2.0.safetensors 
使用模型:anything-v5-PrtRE.safetensors 
常用SD提示词网站导航
1、Prompt Hero.Ai提示词
Prompt Heroes 官网是提供 AI 绘画相关提示词中文网站,包括 Midjourney(MJ)、 Stable Diffusion、DALL-E 等,即使不用提示词在上面找AI绘图也是很不错的选择。我最常用的网站,按照上面的提示和思路再进行自己需求上的改变。
2、AI画廊|提示词
https://www.aigallery.top/?engine=stable
AI画廊官网是一个专注于AI绘画提示词的中文平台,提供丰富的关键词生成器和提示词模板,适用于Stable Diffusion等多种AI绘图工具。即使不熟悉提示词的编写,直接使用该网站生成的关键词也能创作出令人满意的AI绘画作品。
3、PromptoMania MJ和SD提示词生成器
PromptoMania 是一个专注于 AI 绘画提示词生成的社区平台,支持 Midjourney(MJ)和 Stable Diffusion(SD)等多种 AI 绘图工具。它提供了一个强大的提示词生成器,能够帮助用户快速生成高质量的提示词,都可以通过它来优化自己的 AI 绘画创作。
4、AI绘画描述词生成工具
https://www.aigenprompt.com/zh-CN
AI艺术生成工具是一款强大的创意助手,能够根据用户的文本描述生成高质量的图像,适用于广告设计、游戏开发、插画创作等多个领域。
5、图片转提示词 imagetoprompt
ImageToPrompt是一款将图像转换为文本提示的工具,可用于稳定扩散或中途旅程等生成图像模型的输入。
6、AI图片反推关键词 CLIP Interrogator
https://replicate.com/pharmapsychotic/clip-interrogator
CLIP Interrogator 2是一款基于Hugging Face Space的机器学习应用程序,利用CLIP模型实现图像和文本的智能匹配和查询。
7、魔咒百科词典
魔咒百科词典是一款集魔法知识查询与AI绘画标签生成于一体的创新工具,旨在为用户提供便捷的学习与创作体验。
8、Moonvy提示词可视化
Moonvy 提示词工作室是一个功能强大的在线工具,专注于帮助用户通过可视化界面编辑和生成 AI 绘图提示词。
sd提示词网站
以下是一些与 SD 提示词相关的网站和资源:
- MajinAI:MajinAI | Home
- 词图:词图PromptTool - AI绘画资料管理网站
- Black Lily:black_lily
- Danbooru 标签超市:Danbooru 标签超市
- 魔咒百科词典:魔咒百科词典
- AI 词汇加速器:AI 词汇加速器AcceleratorI Prompt
- NovelAI 魔导书:NovelAI 魔导书
- 鳖哲法典:鳖哲法典
- Danbooru tag:Tag Groups Wiki | Danbooru(donmai.us)
- AIBooru:AIBooru:Anime Image Board
在写 SD 提示词时,通常的描述逻辑包括人物及主体特征(服饰、发型发色、五官、表情、动作),场景特征(室内室外、大场景、小细节),环境光照(白天黑夜、特定时段、光、天空),画幅视角(距离、人物比例、观察视角、镜头类型),画质(高画质、高分辨率),画风(插画、二次元、写实)。通过这些详细的提示词,能更精确地控制 Stable Diffusion 的绘图。
对于新手,还有以下功能型辅助网站帮助书写提示词:
- http://www.atoolbox.net/ ,它可以通过选项卡的方式快速填写关键词信息。
- https://ai.dawnmark.cn/ ,每种参数都有缩略图可参考,方便更直观地选择提示词。
- 还可以去 C 站(https://civitai.com/)里面抄作业,每一张图都有详细的参数,可点击下面的复制数据按钮。
此外,还有“Easy Prompt Selector”插件,安装方式是在扩展面板中点击“从网址安装”,然后输入以下地址 https://github.com/blue-pen5805/sdweb-easy-prompt-selector ,然后将汉化包复制进“……\sd-webui-aki-v4\extensions”路径文件夹下直接覆盖。安装完成后,重启 webUI,就可以在生成按钮下面看到多出来一个“提示词”按钮,点击它会出现下拉列表,里面有很多不同的分类,可根据需要选择提示词。
Stable Diffusion教程
地址: https://waytoagi.feishu.cn/wiki/FUQAwxfH9iXqC9k02nYcDobonkf
SD新手:入门图文教程
地址:https://waytoagi.feishu.cn/wiki/PyZqwOe44i6YfekQ0C5ca8tPnKd
【SD】文生图怎么写提示词
地址:https://waytoagi.feishu.cn/wiki/Nx4XwZH4hizXm3kUDxGcOtfZn7g
SD绘画学社
地址:https://waytoagi.feishu.cn/wiki/T6VbwM6rsipZSjkjkBfcFMuCnCe
Stable Diffusion介绍详解
一、Stable Diffusion简介
Stable Diffusion是一种生成对抗网络(GAN)的变体,专注于高质量图像生成。它利用扩散过程和去噪技术逐步生成图像,并且在各类图像生成任务中表现出色。本文将详细介绍Stable Diffusion的原理、实现步骤以及一些实际应用案例。
二、Stable Diffusion的核心原理
2.1 扩散过程(Diffusion Process)
扩散过程是一种从噪声逐渐生成图像的技术。其核心思想是将随机噪声通过一系列逐步去噪的步骤转化为高质量的图像。这个过程包含了以下几个步骤:
- 初始噪声生成:生成一个完全随机的噪声图像。
- 逐步去噪:通过多次迭代,将噪声图像逐步转化为目标图像。
2.2 去噪过程(Denoising Process)
去噪过程使用深度学习模型对噪声图像进行逐步去噪。在每一步,模型会预测当前图像的去噪版本,并且随着步骤的增加,图像的细节逐步清晰。
2.3 模型架构
Stable Diffusion通常采用UNet架构来进行图像生成。UNet是一种常用于图像处理任务的卷积神经网络,具有跳跃连接(skip connections),可以在高分辨率和低分辨率特征之间传递信息。
三、Stable Diffusion的实现步骤
3.1 环境准备
首先,需要准备好运行环境,包括安装必要的库和工具。这里以Python和PyTorch为例。
pip install torch torchvision torchaudio
pip install diffusers3.2 数据准备
为了训练Stable Diffusion模型,需要准备好高质量的图像数据集。这里以CIFAR-10数据集为例。
from torchvision import datasets, transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)3.3 模型定义
定义UNet模型,用于逐步去噪图像。
import torch
import torch.nn as nn
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
# 定义UNet的各个层次
self.encoder = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1),
nn.ReLU(),
nn.ConvTranspose2d(64, 3, kernel_size=4, stride=2, padding=1),
nn.Tanh()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x3.4 训练过程
训练过程中,使用逐步去噪的方式生成图像。
import torch.optim as optim
model = UNet()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(10):
for data in train_loader:
inputs, _ = data
noise = torch.randn_like(inputs)
noisy_inputs = inputs + noise
optimizer.zero_grad()
outputs = model(noisy_inputs)
loss = criterion(outputs, inputs)
loss.backward()
optimizer.step()
print(f"Epoch [{epoch+1}/10], Loss: {loss.item():.4f}")四、实际应用案例
4.1 图像生成
使用训练好的Stable Diffusion模型生成新图像。
import matplotlib.pyplot as plt
model.eval()
with torch.no_grad():
noise = torch.randn(1, 3, 32, 32)
generated_image = model(noise).squeeze().permute(1, 2, 0).numpy()
plt.imshow((generated_image + 1) / 2)
plt.show()4.2 图像修复
Stable Diffusion不仅可以生成图像,还可以用于图像修复。例如,在原神游戏中,如果某些角色的图片损坏,可以通过Stable Diffusion模型修复。
def add_noise(img, noise_factor=0.5):
noisy_img = img + noise_factor * torch.randn_like(img)
return torch.clip(noisy_img, 0., 1.)
# 假设original_image是损坏的原神角色图像
noisy_image = add_noise(original_image)
model.eval()
with torch.no_grad():
restored_image = model(noisy_image.unsqueeze(0)).squeeze().permute(1, 2, 0).numpy()
plt.imshow((restored_image + 1) / 2)
plt.show()五、结论
Stable Diffusion通过逐步去噪的方式实现高质量的图像生成和修复,具有广泛的应用前景。无论是在娱乐领域(如原神角色图像生成)还是在实际应用(如图像修复)中,都能发挥重要作用。
希望这篇博客能帮助你更好地理解和使用Stable Diffusion。如果你有任何问题或建议,欢迎在评论区留言。
文章来源于互联网:Stable Diffusion详解
SD提示词的定义与作用
SD(Stable Diffusion)提示词是用于指导AI生成模型(如Stable Diffusion)生成特定图像或文本内容的关键输入。提示词可以是关键词、短语或句子,通过语义分析和语言生成模型,AI能够理解这些提示词并据此生成符合预期的输出内容。
提示词的分类与使用
- 正向提示词:用于描述想要生成的内容,例如人物、场景、动作等。正向提示词越详细,生成的图像越接近用户期望的效果。
- 反向提示词:用于避免生成某些不希望出现的内容,例如“低分辨率”、“模糊”等,可以帮助提高生成图像的质量和清晰度。
- 预设提示样式:通过预先定义的样式参数(如风格、颜色、形状等),可以快速改变输出结果,以满足不同场景需求。
- 表情提示词:用于控制角色的表情和情绪,例如“微笑”、“害羞”、“愤怒”等。
提示词的设计原则
- 简洁性:提示词应尽量简练,避免过长的句子,因为过长可能导致模型理解困难。
- 明确性:提示词应尽量具体,避免模糊不清的描述,以确保生成结果符合预期。
- 权重设置:合理分配正向和反向提示词的权重,可以优化生成效果。例如,增加正向提示词的权重可以提升生成内容的相关性,而增加反向提示词的权重可以减少不必要的干扰。
提示词的应用场景
- 艺术创作:通过提示词生成高质量的艺术作品,包括人物肖像、风景画等。
- 广告设计:利用提示词快速生成符合客户需求的广告图像。
- 游戏设计:生成游戏角色、场景等。
- 表情控制:通过表情提示词生成特定情绪的角色形象。
提示词库与资源
为了提高提示词的搜索效率和使用效果,许多资源分享了大量优质提示词库。例如:
- 《SD优质提示词库分享》中收录了超过1000条优质提示词,并按类别进行分类。
- 《全网最全SD提示词汇总》提供了包括人像、姿势、服装、反向提示词在内的五类提示词。
- 《Stable Diffusion AI绘画》中附带大量AI绘画提示词和视频生成教程。
提示词优化与进阶技巧
- 组合使用:通过组合不同的提示词,可以实现更复杂的生成效果。例如,结合正向和反向提示词来平衡生成内容的细节和质量。
- 权重调整:通过调整提示词的权重,可以优化生成图像的质量和清晰度。
- 实践与迭代:不断尝试不同的提示词组合和参数设置,以找到最佳的生成效果。
注意事项
- 避免负面内容:在使用SD模型时,需注意收集和避免生成负面或有害内容的提示词。
- 个性化需求:根据具体需求选择合适的提示词类型和风格,以满足不同场景的需求。
总结
SD提示词是AI生成模型的核心输入工具,通过合理设计和优化提示词,可以显著提升生成内容的质量和多样性。无论是艺术创作、广告设计还是表情控制,提示词都扮演着至关重要的角色。同时,利用优质的提示词库和进阶技巧,可以进一步提高工作效率和创意表现。
SD优质提示词库|腾讯文档
【腾讯文档】SD优质提示词库 (需要登录访问)
https://docs.qq.com/sheet/DYUtXVGJJSFZ1R3FF?tab=ss_3qmg50
共收录1000+条优质提示词!增加了418位艺术家风格,主要摘录自Homepage - lib.kalos.art,感兴趣的可以自己进网站看一看,不过需要魔法才行。对文档进行了搜索优化,增加了中文提示词,方便大家进行提示词搜索,增加寻找目标关键词的效率,Ctrl+F或点击搜索,可以直接跳转到想要的提示词!
AI绘画工具-20+常用的AI绘画网站
1、LiblibAl-哩布哩布AI
LiblibAl-哩布哩布AI 是一个智能绘画模型和素材创作平台,目前提供了“在线绘图”和“模型训练”功能。
- 优点:专攻二次元风格,生成的图片风格多样且符合二次元爱好者的需求,操作简单,适合二次元爱好者。
- 缺点:风格较为局限,主要集中在二次元领域,对于其他风格的生成效果可能不够理想。
- 工具地址:https://liblib.ai/
2、即梦AI
即梦AI 是字节跳动推出的产品,仅需输入几个简单的中文词汇,便能创造出高水准的图像。
- 优点:提供丰富的创意风格选择,能够帮助用户快速实现创意想法,生成效果较为独特。
- 缺点:生成速度可能相对较慢,部分用户反馈生成结果的多样性有待提高。
- 工具地址:https://jimeng.jianying.com/s/iDqu5eYc/
3、通义万象
通义万象 是阿里云推出的AI绘画创作大模型,提供“文本生成图像”、“相似图像生成”、“图像风格迁移”和“虚拟模特”等多项功能。
- 优点:支持多种绘画风格,功能较为全面,适合不同需求的用户。
- 缺点:部分功能需要付费解锁,对于初学者来说,学习曲线可能较陡。
- 工具地址:https://wanxiang.aliyun.com/
4、文心一格
文心一格 是百度推出的AI艺术和创意辅助平台,依托于百度的飞桨技术和文心大模型。
- 优点:对中文文本理解能力强,适合中文用户使用,生成的图片风格多样。
- 缺点:生成速度可能不如一些国外工具快,部分用户反馈生成结果的细节处理不够精细。
- 工具地址:https://yige.baidu.com/
5、Vega AI
Vega Al 是一款中文简化版的AI绘画工具,降低了用户上手和使用的难度。
- 优点:生成的图像质量高,细节处理出色,适合专业用户。
- 缺点:使用门槛较高,需要一定的技术背景。
- 工具地址:https://www.vegaai.net/
6、一秒创
一秒创 是一个AI绘画平台,支持快速生成图像。
- 优点:生成速度快,能够快速满足用户的即时需求。
- 缺点:生成结果的稳定性和多样性可能不如一些专业工具。
- 工具地址:https://aigc.yizhentv.com/
7、改图鸭
改图鸭 是一个AI图片编辑工具,支持多种图片修改功能。
- 优点:提供丰富的图像修改功能,适合对已有图像进行优化和调整。
- 缺点:主要功能集中在修改上,生成新图像的能力相对较弱。
- 工具地址:https://www.gaituya.com/
8、库宝AI写作
库宝AI写作 是一个结合写作与绘画的AI工具。
- 优点:能够根据文本内容生成相关的图像,适合创意写作和内容创作。
- 缺点:生成的图像风格较为单一,可能无法满足多样化的需求。
- 工具地址:https://588tool.com/
9、必应(Bing)图像创建
必应官方提供的图像创建工具,基于OpenAI的DALL·E技术,可以快速生成AI绘画。
- 优点:基本完全免费,免安装,支持多种风格的生成。
- 缺点:需要科学上网,位置设置为美国,且需要注册微软账号。
- 工具地址:https://www.bing.com/create (需使用Microsoft Edge浏览器)
10、Deep Dream Generator
Deep Dream Generator 是一个经过数百万张图像训练的神经网络,通过输入文字内容即可生成图片。
- 优点:简单好用,支持多种图片格式和风格。
- 缺点:需要付费使用,功能相对有限。
- 工具地址:https://deepdreamgenerator.com/
11、DeepAI
DeepAI 是一个支持文本到图像生成的AI工具,提供多种风格的图片生成。
- 优点:无需注册即可在线使用,支持多种风格(如油画、插画、赛博朋克等)。
- 缺点:高级功能需要付费解锁。
- 工具地址:https://deepai.org/machine-learning-model/text2img
12、Fotor
Fotor 是一个类似于Canva的设计平台,支持生成多种设计,如海报、传单、封面图等,同时提供AI图片生成功能。
- 优点:功能丰富,支持多种设计需求,适合初学者。
- 缺点:高级功能需要付费,部分用户反馈生成速度较慢。
- 工具地址:https://www.fotor.com/features/ai-image-generator/
13、StarryAI
StarryAI 是一款支持AI绘画的工具,提供多种风格的生成。
- 优点:生成效果多样,支持多种风格的绘画。
- 缺点:需要谷歌或苹果账号登录,部分功能需要付费。
- 工具地址:https://starryai.com/
14、Runway
Runway 是一个AI创作平台,支持多种AI工具,包括AI绘画。
- 优点:功能强大,支持多种AI创作工具,适合专业用户。
- 缺点:需要一定的技术背景才能充分利用其功能。
- 工具地址:https://runwayml.com/
15、NovelAI
NovelAI 是一款以小说创作为主的AI工具,但其绘画功能也非常受欢迎,尤其适合二次元风格的生成。
- 优点:生成的二次元风格图片质量高,适合漫画创作。
- 缺点:需要付费使用,部分用户反馈生成速度较慢。
- 工具地址:https://novelai.net
16、6pen Art
6pen Art 是国内团队出品的AI绘画工具,支持多种绘画风格。
- 优点:支持中文,操作简单,适合绘画初学者。
- 缺点:功能相对有限,适合简单的绘画需求。
- 工具地址:https://6pen.art/
17、NightCafe Creator
NightCafe Creator 是一个国外的AI绘画工具,输入文字描述即可生成图片。
- 优点:免费试用,适合初学者快速上手。
- 缺点:生成速度较慢,部分功能需要付费。
- 工具地址:https://creator.nightcafe.studio/
18、DALL·E 2
DALL·E 2 是OpenAI旗下的AI绘画工具,支持文生图和图片编辑功能。
- 优点:生成效果高质量,支持多种图片编辑功能。
- 缺点:需要科学上网,部分功能需要付费。
- 工具地址:https://labs.openai.com/
19、Adobe Firefly
Adobe Firefly 是Adobe公司推出的AI绘画工具,目前处于测试阶段。
- 优点:功能强大,适合Adobe用户,支持多种绘画风格。
- 缺点:需要申请内测账户,目前仅支持美国区域。
- 工具地址:https://firefly.adobe.com/
20、Flux
Flux 是由Stable Diffusion的核心开发者创立的AI绘画模型,号称目前最强的开源AI绘画模型。
- 优点:开源免费,支持本地部署及模型微调,适合专业用户。
- 缺点:需要一定的技术背景才能充分利用其功能。
- 工具地址:https://blackforestlabs.ai/
21、Ideogram
Ideogram 是一款支持AI绘画的工具,提供多种风格的生成。
- 优点:生成效果多样,支持多种风格的绘画。
- 缺点:需要付费使用,部分功能需要高级账户。
- 工具地址:https://ideogram.ai/